|
|
| (사용자 2명의 중간 판 9개는 보이지 않습니다) |
| 2번째 줄: |
2번째 줄: |
| | | | |
| | == 개요 == | | == 개요 == |
| − | 자료구조는 컴퓨터 과학에서 효율적인 접근 및 수정을 가능케 하는 자료의 조직, 관리, 저장을 의미한다. 더 정확히 말해, 자료 구조는 데이터 값의 모임, 또 데이터 간의 관계, 그리고 데이터에 적용할 수 있는 함수나 명령을 의미한다. 신중히 선택한 자료구조는 보다 효율적인 알고리즘을 사용할 수 있게 한다. 이러한 자료구조의 선택문제는 대개 추상 자료형의 선택으로부터 시작하는 경우가 많다. 효과적으로 설계된 자료구조는 실행시간 혹은 메모리 용량과 같은 자원을 최소한으로 사용하면서 연산을 수행하도록 해준다. 자료구조에는 여러 종류가 있으며, 이러한 각각의 자료구조는 각자의 연산 및 목적에 맞추어져 있다. 예를 들어 B-트리는 데이터베이스에 효율적이며, 라우팅 테이블은 네트워크(인터넷, 인트라넷)에 일반적이다. 다양한 프로그램을 설계할 때, 어떠한 자료구조를 선택할지는 가장 우선적으로 고려되어야 한다. 이는 큰 시스템을 제작할 때 구현의 난이도나 최종 결과물의 성능이 자료구조에 크게 의존한다는 것을 많은 경험이 뒷받침하기 때문이다. 일단 자료구조가 선택되면 적용할 알고리즘은 상대적으로 명확해지기 마련이다. 때로는 반대 순서로 정해지기도 하는데, 이는 목표로 하는 연산이 특정한 알고리즘을 반드시 필요로 하며, 해당 알고리즘은 특정 자료구조에서 가장 나은 성능을 발휘할 때와 같은 경우이다. 어떠한 경우든, 적절한 자료구조의 선택은 필수적이다. 이러한 관점은 알고리즘보다 자료구조가 보다 중요한 요소로 적용되는 많은 정형화된 개발론 그리고 프로그래밍 언어의 개발을 촉발시켰다. 대부분의 언어는 일정 수준의 모듈개념을 가지고 있으며, 이는 자료구조가 검증된 구현은 감춘 채 인터페이스만을 이용하여 다양한 프로그램에서 사용되는 것을 가능하게 해준다. C++, 자바와 같은 객체지향 프로그래밍 언어는 특별히 이러한 목적으로 객체를 사용한다. 이러한 자료구조의 중요성으로 말미암아, 최근의 프로그래밍 언어 및 개발 환경은 다양한 표준 라이브러리를 제공하고 있다. 예로, C++의 표준 템플릿 라이브러리나 자바의 자바 API, 마이크로소프트 .NET과 같은 것들을 들 수 있다. 자료구조에서 가장 기초적인 단위는 행렬, 레코드, 유니온, 참조와 같은 것이다. 예를 들어, Nullable 참조는 참조와 유니온의 조합으로 나타낼 수 있으며, 가장 단순한 자료구조 가운데 하나인 연결 리스트는 레코드와 Nullable 참조로 나타낼 수 있다.<ref name='synopsis'>위키백과, 〈[https://ko.wikipedia.org/wiki/%EC%9E%90%EB%A3%8C_%EA%B5%AC%EC%A1%B0 자료구조 ]〉</ref> | + | 자료구조는 컴퓨터 과학에서 효율적인 접근 및 수정을 가능케 하는 자료의 조직, 관리, 저장을 의미한다. 더 정확히 말해, 자료 구조는 데이터 값의 모임, 또 데이터 간의 관계, 그리고 데이터에 적용할 수 있는 함수나 명령을 의미한다. 신중히 선택한 자료구조는 보다 효율적인 알고리즘을 사용할 수 있게 한다. 이러한 자료구조의 선택문제는 대개 추상 자료형의 선택으로부터 시작하는 경우가 많다. 효과적으로 설계된 자료구조는 실행시간 혹은 메모리 용량과 같은 자원을 최소한으로 사용하면서 연산을 수행하도록 해준다. 자료구조에는 여러 종류가 있으며, 이러한 각각의 자료구조는 각자의 연산 및 목적에 맞추어져 있다. 예를 들어 B-트리는 데이터베이스에 효율적이며, 라우팅 테이블은 네트워크(인터넷, 인트라넷)에 일반적이다. 다양한 프로그램을 설계할 때, 어떠한 자료구조를 선택할지는 가장 우선적으로 고려되어야 한다. 이는 큰 시스템을 제작할 때 구현의 난이도나 최종 결과물의 성능이 자료구조에 크게 의존한다는 것을 많은 경험이 뒷받침하기 때문이다. 일단 자료구조가 선택되면 적용할 알고리즘은 상대적으로 명확해지기 마련이다. 때로는 반대 순서로 정해지기도 하는데, 이는 목표로 하는 연산이 특정한 알고리즘을 반드시 필요로 하며, 해당 알고리즘은 특정 자료구조에서 가장 나은 성능을 발휘할 때와 같은 경우이다. 어떠한 경우든, 적절한 자료구조의 선택은 필수적이다. 이러한 관점은 알고리즘보다 자료구조가 보다 중요한 요소로 적용되는 많은 정형화된 개발론 그리고 프로그래밍 언어의 개발을 촉발시켰다. 대부분의 언어는 일정 수준의 모듈개념을 가지고 있으며, 이는 자료구조가 검증된 구현은 감춘 채 인터페이스만을 이용하여 다양한 프로그램에서 사용되는 것을 가능하게 해준다. C++, 자바와 같은 객체지향 프로그래밍 언어는 특별히 이러한 목적으로 객체를 사용한다. 이러한 자료구조의 중요성으로 말미암아, 최근의 프로그래밍 언어 및 개발 환경은 다양한 표준 라이브러리를 제공하고 있다. 예로, C++의 표준 템플릿 라이브러리나 자바의 자바 API, 마이크로소프트 .NET과 같은 것들을 들 수 있다. 자료구조에서 가장 기초적인 단위는 행렬, 레코드, 유니온, 참조와 같은 것이다. 예를 들어, Nullable 참조는 참조와 유니온의 조합으로 나타낼 수 있으며, 가장 단순한 자료구조 가운데 하나인 연결리스트는 레코드와 Nullable 참조로 나타낼 수 있다.<ref name='synopsis'>위키백과, 〈[https://ko.wikipedia.org/wiki/%EC%9E%90%EB%A3%8C_%EA%B5%AC%EC%A1%B0 자료구조 ]〉</ref> |
| | | | |
| | == 특징 == | | == 특징 == |
| 19번째 줄: |
19번째 줄: |
| | 자료구조를 이용하여 데이터를 처리할 경우 해당 자료구조의 인터페이스만 이용하여 데이터를 처리하도록 하므로 모듈화가 가능하다. 이는 자료구조를 설계할 때 특정 프로그램에 맞추어 설계하지 않고 다양한 프로그램에서 사용될 수 있도록 범용화하여 설계함으로써 가능하다. | | 자료구조를 이용하여 데이터를 처리할 경우 해당 자료구조의 인터페이스만 이용하여 데이터를 처리하도록 하므로 모듈화가 가능하다. 이는 자료구조를 설계할 때 특정 프로그램에 맞추어 설계하지 않고 다양한 프로그램에서 사용될 수 있도록 범용화하여 설계함으로써 가능하다. |
| | | | |
| − | == 분류 == | + | == 종류 == |
| | [[파일:자료구조_분류.png]] | | [[파일:자료구조_분류.png]] |
| − | === 선형 구조 ===
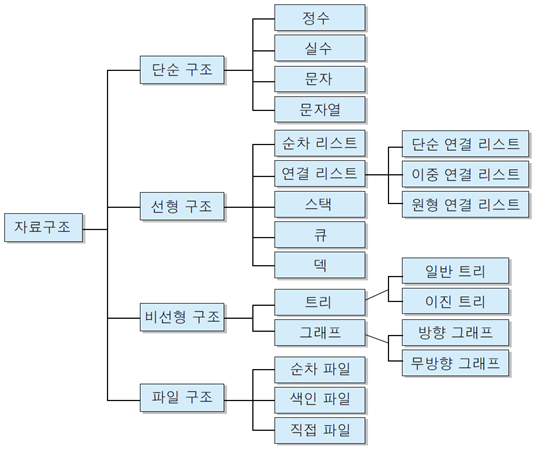
| + | * 자료구조의 종류로는 선형구조, 비선형구조로 구성되어 있으며 선형 구조로는 [[선형 리스트]], [[연결리스트]], [[스택]], [[큐]], [[덱]]이 있고, 비선형 구조로는 [[트리]]와 [[그래프]]가 있다. |
| − | * '''선형 구조''' : 데이터가 연속적으로 연결되어 있는 모양으로 구성하는 방법이다. | |
| − | 배열과 같이 연속되는 기억장소에 저장되는 리스트이며, 포인터 등을 사용하여 자료를 연결하면 그 결과가 자료에 일직선상에 표시되거나 하나의 원상에 표시되는 구조이다.
| |
| − | ==== 선형 리스트(Linear List) ====
| |
| − | * '''선형 리스트(Linear List)''' : 배열과 같이 연속되는 기억장소에 저장되는 리스트이다.
| |
| − | ===== 장단점 =====
| |
| − | * 장점
| |
| − | 저장 효율이 뛰어나고 접근 속도가 빠르며 간단한 자료 구조이다.<ref name='linear_list'>S.Zinlee,〈[https://zinlee.tistory.com/entry/%EC%84%A0%ED%98%95-%EB%A6%AC%EC%8A%A4%ED%8A%B8Linear-List%EC%99%80-%EC%97%B0%EA%B2%B0-%EB%A6%AC%EC%8A%A4%ED%8A%B8Linked-List 선형 리스트와 연결 리스트 ]〉, 2011년 8월 12일</ref>
| |
| − | | |
| − | * 단점
| |
| − | 삽입, 삭제가 어렵다. (끝값은 쉽지만 중간값을 삽입, 삭제 시 그 이후의 값을 전부 복사 후 처리해야 한다.)<ref name='linear_list'></ref>
| |
| − | ==== 연결 리스트(Linked List) ====
| |
| − | * '''연결 리스트(Linked List)''' : 자료들을 반드시 연속적으로 배열시키지는 않고 임의의 기억공간에 기억시키되, 자료 항목의 순서에 따라 노드의 포인터 부분을 이용하여 서로 연결시킨 자료 구조이다.<ref name='linked_list_def'>코딩팩토리,〈[https://coding-factory.tistory.com/228]〉, 2018년 8월 22일</ref>
| |
| − | ===== 장단점 =====
| |
| − | * 장점
| |
| − | 링크로써 구현되어있기 때문에, 자료를 추가하거나 삭제할 시에 링크만 바꿔주면 되기 때문에 추가, 삭제가 용이하다.(추가 원소 이동 연산이 불필요하다.)<br>
| |
| − | 메모리 효율성이 우수하다.<br>
| |
| − | 필요할 때마다 데이터 추가, 삭제할 수 있기 때문에 배열 리스트처럼 최대 원소 개수 지정이 필요 없다.<ref name='linked_list2'>요시,〈[https://m.blog.naver.com/PostView.nhn?blogId=tjsrudv&logNo=221055137174&proxyReferer=https:%2F%2Fwww.google.com%2F 배열 리스트와 연결 리스트의 차이 (장단점)]〉, 2017년 7월 19일</ref>
| |
| − | * 단점
| |
| − | 원하는 원소를 찾을 때까지 포인터로 노드를 탐색해야 하기 때문에 탐색 연산의 비용이 높고 구현이 어렵다.<ref name='linked_list2'></ref><br>
| |
| − | ===== 단순 연결 리스트 =====
| |
| − | ===== 이중 연결 리스트 =====
| |
| − | ===== 원형 연결 리스트 =====
| |
| − | | |
| − | ==== 스택(Stack) ====
| |
| − | * '''스택(Stack)''' : 후입선출(後入先出, Last In First Out; LIFO)의 자료구조이다. 데이터 저장소에서 새로 들어오는 데이터의 위치가 저장소의 끝 부분(Top 혹은 Top pointer라고 한다)이고, 써먹기 위해 내보내는 데이터 역시 저장소의 끄트머리에서 나간다. 입력은 push, 출력은 pop이다. peek는 Top의 위치에 있는 데이터를 확인하는 것을 말한다.<ref name='stack'>나무위키,〈[https://namu.wiki/w/%EC%8A%A4%ED%83%9D(%EC%9E%90%EB%A3%8C%EA%B5%AC%EC%A1%B0) 스택(자료구조)]〉</ref>
| |
| − | ===== 입/출력 방식 =====
| |
| − | [[파일:자료구조_스택.png|600픽셀]]<ref name='stack_1'>Lkt_Programmer,〈[https://lktprogrammer.tistory.com/46 스택(Stack) 자료 구조 ]〉, 2017년 9월 28일 </ref><br>
| |
| − | 1. 가장 먼저 5를 PUSH 한다. 스택 자료 구조에 가장 아래에 위치하게 된다.<br>
| |
| − | 2. 차례대로 PUSH 4, PUSH 3을 한 결과이다.<br>
| |
| − | 3. POP 2회를 실시하게 되면 출력 결과는 3,4가 된다. 즉 3은 가장 나중에 입력 되었지만 가장 먼저 출력이 된다.<ref name='stack_1'></ref>
| |
| − | ==== 큐(Queue) ====
| |
| − | * '''큐(Queue)''' : 선형 리스트의 한쪽에서는 삽입, 다른 한쪽에서는 삭제 작업이 이루어지도록 구성한 자료구조이다.
| |
| − | :가장 먼저 삽입된 자료가 가장 먼저 삭제되는 선입선출(FIFO : First In First Out) 구조이다.<ref name='queue'>Mr.lee,〈[https://lee-mandu.tistory.com/462 자료 구조의 개념 정리]〉, 2019년 9월 10일</ref>
| |
| − | ===== 선형 큐(Linear Queue) =====
| |
| − | * '''선형 큐(Linear Queue)''' : 선형 큐는 데이터를 집어넣는 Enqueue 기능과 데이터를 내보내는 Dequeue 기능을 제공한다.<ref name='enqueue_1'>Lkt_Programmer,〈[https://lktprogrammer.tistory.com/47?category=676210 선형 큐(Linear Queue) 자료 구조]〉, 2017년 9월 29일 </ref>
| |
| − | ====== 입력(Enqueue) ======
| |
| − | [[파일:선형_큐.PNG]]<ref name='enqueue_1'></ref>
| |
| − | ====== 출력(Dequeue) ======
| |
| − | [[파일:선형큐_dequeue.png]]<ref name='enqueue_1'></ref>
| |
| − | ===== 원형 큐(Circular Queue) =====
| |
| − | * '''원형 큐(Circular Queue)''' : 원형 큐는 선형 큐의 문제점을 보완하기 위한 자료구조이다. 선형큐의 문제점은 rear이 가리키는 포인터가 배열의 마지막 인덱스를 가리키고 있을 때 앞쪽에서 Dequeue로 발생한 배열의 빈 공간을 활용할 수 없는데, 원형큐에서는 포인터 증가 방식이 (rear+1)%arraysize 형식으로 변환하기 때문에 배열의 첫 인덱스부터 다시 데이터의 삽입이 가능해진다.<ref name='circular_queue'>Lkt_Programmer,〈[https://lktprogrammer.tistory.com/59?category=676210 원형 큐 (Circular Queue) 자료 구조]〉, 2017년 10월 13일 </ref>
| |
| − | ====== 입력(Enqueue) ======
| |
| − | rear값을 1 증가시키면서 해당 인덱스에 데이터를 삽입시킨다. 이때, (rear+1) % array.length 조건을 통해서 원형큐가 꽉찬 상태인지 확인한다. 예를들어, 큐의 사이즈는 4이고 enqueue(1),enqueue(2),enqueue(3)을 수행하고 euqueue(4)를 수행하면 (3+1) % 4 == front 이므로 enqueue를 수행할 수 없다.<ref name='circular_queue2'>syunyun,〈[https://syundev.tistory.com/36 원형 큐]〉, 2019년 12월 20일 </ref>
| |
| − | | |
| − | ====== 출력(Dequeue) ======
| |
| − | front의 포인터를 1 증가시면서 데이터를 제거한다.<ref name='circular_queue2'></ref>
| |
| − | ===== 덱(Deque) =====
| |
| − | * '''덱(Deque)''' : Double-ended queue의 약자로, 양 끝에서만 데이터를 넣고 양 끝에서 뺄 수 있는 자료구조이다. 큐는 push, pop을 할 수 있는 위치가 한 방향으로 고정되어 있지만, 덱은 앞에서도 push, pop, 뒤에서도 push, pop이 모두 가능하다.<ref name='deque'>ldgeao99,〈[https://ldgeao99.tistory.com/249 자료구조 덱]〉, 2019년 4월 23일 </ref>
| |
| − | ====== 입/출력 방식 ======
| |
| − | [[파일:덱_입출력.png]]<ref name='deque'></ref><br>
| |
| − | | |
| − | === 비선형 구조 ===
| |
| − | * '''비선형 구조''' : 일렬로 나열하기 힘들고 자료의 순서가 불규칙해서 연결 관계가 복잡한 구조이다. <ref name='non_linear'>사이언스올,〈[https://www.scienceall.com/%EB%B9%84%EC%84%A0%ED%98%95-%EA%B5%AC%EC%A1%B0nonlinear-structure/ 비선형 구조]〉, 2018년 12월 12일</ref>
| |
| − | ==== 트리 ====
| |
| − | * '''트리(Tree)''' : 트리는 일반적으로 대상 정보의 각 항목들을 계층적으로 연관되도록 구조화시키고자 할 때 사용하는 비선형 자료구조이다.
| |
| − | :데이터 요소들의 단순한 나열이 아닌 부모-자식 관계의 계층적 구조로 표현이 된다.
| |
| − | ===== 구성 =====
| |
| − | [[파일:트리.png|600픽셀]]<ref name='tree'>adam2,〈[https://velog.io/@adam2/TREE 자료구조 Tree]〉, 2020년 4월 5일</ref> <br> | |
| − | * node: 트리를 구성하고 있는 각 요소
| |
| − | * Edge(간선): 트리를 구성하기 위해 노드와 노드를 연결하는 선
| |
| − | * Root Node: 최상위 계층에 존재하는 노드
| |
| − | * level: 트리의 특정 깊이를 가지는 노드의 집합
| |
| − | * degree(차수): 하위 트리 개수 / 간선 수 (degree) = 각 노드가 지닌 가지의 수
| |
| − | * Terminal Node ( = leaf Node, 단말 노드) : 하위에 다른 노드가 연결되어 있지 않은 노드
| |
| − | * Internal Node (내부노드, 비단말 노드) : 단말 노드를 제외한 모든 노드로 루트 노드를 포함한다.<ref name='tree'></ref>
| |
| − | ===== 이진 트리(Binary Tree) =====
| |
| − | * '''이진 트리(Binary Tree)''' : 이진트리는 트리를 구성하는 노드들의 최대 차수(degree)가 2인 노드들로 구성되는 트리이다.
| |
| − | :이진트리의 레벨 i에서 가질 수 있는 최대 노드의 수는 2^i이다. (i>=0)
| |
| − | :깊이가 k인 이진트리가 가질 수 있는 최대 노드의 수는 2^k-1이다.(k>=1)
| |
| − | :이진트리는 완전 이진 트리(Completable Binary Tree)와 포화 이진 트리(Perfect Binary Tree), 전 이진 트리(Full Binary Tree)라고 하는 특별한 트리 구조를 정의할 수 있다.<ref name='tree'></ref>
| |
| − | ====== 완전 이진 트리(Completable Binary Tree) ======
| |
| − | [[파일:완전이진트리.png|700픽셀]]<ref name='tree'></ref><br> | |
| − | :트리를 구성하고 있는 임의의 두 단말 노드의 레벨 차이가 1 이하이고 마지막 레벨을 제외한 모든 레벨에 존재할 수 있는 모든 노드를 갖고 있으며, 왼쪽에서 오른쪽으로 채워지는 이진트리이다.
| |
| − | | |
| − | ====== 전 이진 트리(Full Binary Tree) ======
| |
| − | [[파일:전이진트리.png|700픽셀]]<ref name='tree'></ref><br>
| |
| − | :모든 노드가 0개 또는 2개의 자식 노드를 갖는 트리이다.
| |
| − | | |
| − | ====== 포화 이진 트리(Perfect Binary Tree) ======
| |
| − | :모든 레벨에 노드가 차있는 상태로 최대 노드 수인 2^k-1개로 채워져 있는 트리이다.
| |
| − | :전 이진 트리이면서 완전 이진 트리인 경우이다.<ref name='tree'></ref>
| |
| − | ==== 그래프 ====
| |
| − | ===== 방향 그래프 =====
| |
| − | ===== 무방향 그래프 =====
| |
| − | | |
| − | === 파일 구조 ===
| |
| − | ==== 순차 파일 ====
| |
| − | | |
| − | ==== 색인 파일 ====
| |
| − | | |
| − | ==== 직접 파일 ====
| |
| | {{각주}} | | {{각주}} |
| | | | |
| | == 참고자료 == | | == 참고자료 == |
| − | | + | * islove8587, 〈[https://m.blog.naver.com/PostView.nhn?blogId=islove8587&logNo=220548856458&proxyReferer=https:%2F%2Fwww.google.com%2F 자료구조란 ]〉 |
| | + | * 위키백과, 〈[https://ko.wikipedia.org/wiki/%EC%9E%90%EB%A3%8C_%EA%B5%AC%EC%A1%B0 자료구조 ]〉 |
| | == 같이 보기 == | | == 같이 보기 == |
| − | * [[C언어]] | + | * [[선형구조]] |
| − | * [[자바]] | + | * [[비선형구조]] |
| − | * [[파이썬]]
| |
| − | * [[객체지향 프로그래밍]]
| |
| − | * [[프로그래밍 언어]]
| |
| | | | |
| − | {{프로그래밍|검토 필요}} | + | {{데이터|검토 필요}} |
자료구조(資料構造, data structure)란, 자료의 집합을 의미하며 각 원소들 사이의 관계가 논리적으로 정의된 일정한 규칙에 의하여 나열되며 자료에 대한 처리를 효율적으로 수행할 수 있도록 자료를 조직적, 체계적으로 구분하여 표현한 것을 말한다. [1]
자료구조는 컴퓨터 과학에서 효율적인 접근 및 수정을 가능케 하는 자료의 조직, 관리, 저장을 의미한다. 더 정확히 말해, 자료 구조는 데이터 값의 모임, 또 데이터 간의 관계, 그리고 데이터에 적용할 수 있는 함수나 명령을 의미한다. 신중히 선택한 자료구조는 보다 효율적인 알고리즘을 사용할 수 있게 한다. 이러한 자료구조의 선택문제는 대개 추상 자료형의 선택으로부터 시작하는 경우가 많다. 효과적으로 설계된 자료구조는 실행시간 혹은 메모리 용량과 같은 자원을 최소한으로 사용하면서 연산을 수행하도록 해준다. 자료구조에는 여러 종류가 있으며, 이러한 각각의 자료구조는 각자의 연산 및 목적에 맞추어져 있다. 예를 들어 B-트리는 데이터베이스에 효율적이며, 라우팅 테이블은 네트워크(인터넷, 인트라넷)에 일반적이다. 다양한 프로그램을 설계할 때, 어떠한 자료구조를 선택할지는 가장 우선적으로 고려되어야 한다. 이는 큰 시스템을 제작할 때 구현의 난이도나 최종 결과물의 성능이 자료구조에 크게 의존한다는 것을 많은 경험이 뒷받침하기 때문이다. 일단 자료구조가 선택되면 적용할 알고리즘은 상대적으로 명확해지기 마련이다. 때로는 반대 순서로 정해지기도 하는데, 이는 목표로 하는 연산이 특정한 알고리즘을 반드시 필요로 하며, 해당 알고리즘은 특정 자료구조에서 가장 나은 성능을 발휘할 때와 같은 경우이다. 어떠한 경우든, 적절한 자료구조의 선택은 필수적이다. 이러한 관점은 알고리즘보다 자료구조가 보다 중요한 요소로 적용되는 많은 정형화된 개발론 그리고 프로그래밍 언어의 개발을 촉발시켰다. 대부분의 언어는 일정 수준의 모듈개념을 가지고 있으며, 이는 자료구조가 검증된 구현은 감춘 채 인터페이스만을 이용하여 다양한 프로그램에서 사용되는 것을 가능하게 해준다. C++, 자바와 같은 객체지향 프로그래밍 언어는 특별히 이러한 목적으로 객체를 사용한다. 이러한 자료구조의 중요성으로 말미암아, 최근의 프로그래밍 언어 및 개발 환경은 다양한 표준 라이브러리를 제공하고 있다. 예로, C++의 표준 템플릿 라이브러리나 자바의 자바 API, 마이크로소프트 .NET과 같은 것들을 들 수 있다. 자료구조에서 가장 기초적인 단위는 행렬, 레코드, 유니온, 참조와 같은 것이다. 예를 들어, Nullable 참조는 참조와 유니온의 조합으로 나타낼 수 있으며, 가장 단순한 자료구조 가운데 하나인 연결리스트는 레코드와 Nullable 참조로 나타낼 수 있다.[2]
상황에 맞는 알고리즘을 사용하여 자료를 구조화 시키기 때문에 효율적으로 동작한다.
예를 들어 모든 사원에 대해 사번과 이름의 쌍을 배열이라는 자료구조로 만들었을 때 사번을 가지고 이름을 찾을 경우 배열은 인덱스를 이용하여 데이터를 저장하기 때문에 찾으려는 사번이 첫번째 인덱스에 저장되어 있을 경우 한번의 검색으로 찾을 수 있지만 최악의 경우 제일 마지막 인덱스에 위치할 수 있으므로 데이터의 수만큼 검색을 해야 한다.
평균적으로 자료수/2 만큼의 검색을 해야 하므로 데이터를 찾는 작업이 빈번하고 데이터가 많을 경우 그다지 효율적이지 못하다. 이럴 때에는 해시 테이블과 같은 자료구조를 이용하여 좀 더 빠르게 검색 작업을 할 수 있다.
이처럼 상황에 맞는 적절한 자료구조를 이용하게 되면 데이터 처리의 효율을 높일 수 있다.
추상화란 복잡한 자료, 모듈, 시스템 등으로부터 핵심적인 개념 또는 기능을 간추려내는 것을 말한다.
자료구조를 이용하여 데이터를 처리할 경우 처리할 데이터를 어떻게 삽입하고 어떻게 추출할 것인가에 중점을 두지 않는다. 즉, 자료구조 자체를 구현하는 알고리즘에 중점을 두지 않고 어느 시점에 데이터를 삽입할 것이며 어느 시점에 데이터를 추출하고 이러한 데이터를 어떻게 사용할 것인지에 초점을 맞출 수 있기 때문에 프로그램의 비즈니스적인 요소에 좀 더 시간을 할애할 수 있다.
데이터를 처리하는 관점에서 보면 특정 자료구조 자체의 내부 구현은 그리 중요하지 않기 때문에 어떻게 구현했는지 보다 어떻게 사용하는지에 대해서 알고 있으면 된다.
예를 들어 스택(Stack)의 경우 가장 마지막에 삽입한 데이터를 가장 먼저 꺼내는 자료구조이고 push(), pop() 메소드를 통해서 데이터를 삽입하고 꺼낼 수 있다.
그리고 이러한 자료구조의 추상화는 실제 구현한 언어가 무엇인지에 따라 실제 그 코드는 다르지만 추상적인 개념에 대해서만 알고 있으면 되기 때문에 언어에 종속적이지 않다는 특징을 가진다.
자료구조를 이용하여 데이터를 처리할 경우 해당 자료구조의 인터페이스만 이용하여 데이터를 처리하도록 하므로 모듈화가 가능하다. 이는 자료구조를 설계할 때 특정 프로그램에 맞추어 설계하지 않고 다양한 프로그램에서 사용될 수 있도록 범용화하여 설계함으로써 가능하다.
참고자료[편집]
같이 보기[편집]
|
 이 자료구조 문서는 데이터에 관한 글로서 검토가 필요합니다. 위키 문서는 누구든지 자유롭게 편집할 수 있습니다. [편집]을 눌러 문서 내용을 검토·수정해 주세요. 이 자료구조 문서는 데이터에 관한 글로서 검토가 필요합니다. 위키 문서는 누구든지 자유롭게 편집할 수 있습니다. [편집]을 눌러 문서 내용을 검토·수정해 주세요.
|
| 개발 : 프로그래밍, 소프트웨어, 데이터 □■⊕, 솔루션, 보안, 하드웨어, 컴퓨터, 사무자동화, 인터넷, 모바일, 사물인터넷, 게임, 메타버스, 디자인
|
|
|
| 데이터
|
ACID • CRUD • CSV • DAO • DB • DBMS • DB 명령어 • DCL • DDL • DML • DTO • ERD • ETL • JDBC • LOD • MDM • ODBC • RDBMS • RDF • SQL • 가상 데이터베이스 • 관계형 데이터베이스 • 그래프 • 기본키(PK) • 내부조인 • 널 • 노드 • 다이어그램 • 대리키 • 대체키 • 데이터 • 데이터댐 • 데이터마트 • 데이터 모델링 • 데이터뱅크 • 데이터베이스(DB) • 데이터베이스 언어 • 데이터 사이언스 • 데이터 사전 • 데이터 웨어하우스 • 데이터 정의어(DDL) • 데이터 제어어(DCL) • 데이터 조작어(DML) • 데이터 클러스터 • 데이터 토큰 (문자열) • 데이터 통합 • 덱 • 디비서버 • 라이트조인 • 락 • 레코드 • 레프트조인 • 로그 • 로그파일 • 로깅 • 롤백 • 리두로그 • 릴레이션 • 마스터데이터 • 마스터데이터관리(MDM) • 마이그레이션 • 메타데이터 • 배열 • 뷰 • 빅데이터 • 서브쿼리 • 수퍼키 • 순차리스트 • 스키마 • 스택 • 슬로우쿼리 • 엔티티 • 역정규화 • 연결리스트 • 외래키(FK) • 외부조인 • 인덱스 • 인덱싱 • 인젝션 • 자료구조 • 정규화 • 정보 • 조인 • 커밋 • 쿼리 • 큐 • 키 • 타깃 • 테이블 • 튜플 • 트랜잭션 • 트리 • 트리거 • 티비마이그레이터 • 풀조인 • 프로시저 • 필드 • 해시 • 해시맵 • 해시태그 • 해시테이블 • 해시함수 • 해싱 • 후보키
|
|
|
데이터베이스
관리 시스템
(DBMS)
|
관계형 데이터베이스 관리 시스템(RDBMS) • 노에스큐엘(NoSQL) • 데이터베이스 관리 시스템(DBMS) • 더비 • 디비투(DB2) • 레디스 • 마리아디비(MariaDB) • 마이에스큐엘(MySQL) • 몽고디비 • 빅테이블 • 사이베이스 • 선디비 • 알티베이스 • 액세스 • 에스큐엘(SQL) • 에스큐엘라이트(SQLite) • 에이치베이스 • 엠에스에스큐엘(MS-SQL) • 오라클(Oracle) • 인터베이스 • 인포믹스 • 카산드라 • 카우치디비 • 큐브리드 • 티베로 • 파이어버드 • 포스트그레스큐엘(PostgreSQL) • 하이퍼테이블
|
|
|
| DB 명령어
|
alter • array • create • delete • drop • from • full join • grant • inner join • insert • join • left join • null • order by • outer join • rename • revoke • right join • select • truncate • update • where
|
|
|
| 시스템 연계
|
API • CGI • EAI • ESB • JPA • RSS • SOA • SOAP • SSL • SSO • web3.js • XML • 디비투디비(DB-to-DB) • 레스트풀(RESTful) • 상호운용성 • 시스템 인터페이스 • 신디케이션 API • 오픈 API • 웹 API • 웹개방성 • 윈도우 API • 자바 API • 크롤링 • 프라이빗 API
|
|
|
| 위키 : 자동차, 교통, 지역, 지도, 산업, 기업, 단체, 업무, 생활, 쇼핑, 블록체인, 암호화폐, 인공지능, 개발, 인물, 행사, 일반
|
|

 위키원
위키원






