
 위키원
위키원



테이블 (데이터베이스)
테이블(table)은 행(row)과 열(column)로 구성된 데이터 집합(값)의 모임이다. 관계형 데이터베이스(relational database)에서 사용되는 용어이다.
개요
테이블(table)은 데이터베이스(database) 상 특정한 종류의 데이터를 구조적으로 묶은 것이다.
구조
테이블은 기본적으로 행(row)과 열(column)으로 구성되어 있다.
- 데이터베이스 상에서 정의되는 행(row)
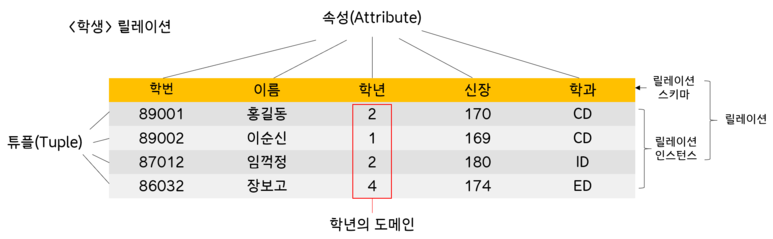
- 레코드(record), 튜플(tuple) : 릴레이션이 나타내는 엔티티(entity)의 특정 인스턴스에 관한 사실(값)들의 모임이다. 튜플로 통용된다.
- 카디날리티(cardinality) : 릴레이션 튜플의 개수
- 데이터베이스 상에서 정의되는 열(column)
- 속성(attribute, 애트리뷰트) : 하나의 릴레이션은 현실세계의 어떤 개체(entity)를 표현하고 저장되는 데 사용된다.
- 이때 개체는 사물이 될 수도, 추상적인 개념이 될 수도 있다.
- 필드(field) : 종종 컬럼의 대용으로 동일한 의미로 사용되지만, 필드와 필드값은 한 열이나 한 컬럼 사이의 교차로 존재하는 단일 항목을 특정할 때 언급하는 것이다.
- 차수(degree) : 한 릴레이션에 들어 있는 애트리뷰트의 수
- 도메인(domain) : 하나의 애트리뷰트가 취할 수 있는 같은 타입의 원자값들의 집합
- 도메인은 하나의 애트리뷰트가 취할 수 있는 같은 타입의 원자값들의 집합이다.
- 도메인은 실제 애트리뷰트 값이 나타날 때 그 값의 합법 여부를 시스템이 검사하는데 이용된다.
- 릴레이션 인스턴스(relation instance)
- 데이터 개체를 구성하고 있는 속성들에 데이터 타입이 정의되어 구체적인 데이터 값을 갖고 있는 것을 말한다.
- 관계형 데이터베이스 구조

세부항목
엔티티
엔티티(entity)는 데이터베이스에 표현하려고 하는 유형, 무형의 객체로서 서로 구별되는 것을 뜻한다. 이 개체는 현실 세계에 대해 사람이 생각하는 개념이나 정보의 단위로서 의미를 가지고 있다. 이것은 컴퓨터가 취급하는 파일의 레코드(record)에 대응한다. 이 개체는 그 단독으로 존재할 수 있으며, 정보로서의 역할을 한다. 하나의 개체는 하나 이상의 속성, 즉 애트리뷰트(attribute)로 구성되고 각 속성은 그 개체의 특성이나 상태를 기술해 준다. 예를 들어, 학생이라는 개체는 학번, 이름, 학과라는 3개의 속성들로 구성되어 있다. 이 때 학번, 이름, 학과는 학생이라는 개체가 가지고 있는 특성, 즉 값을 나타내고 있는 것이다. 이와 같이 속성, 즉 애트리뷰트(attribute)라고 하는 것은 이름을 가진, 데이터의 가장 작은 논리적 단위가 된다. 보통 파일 구조에서는 데이터 항목(data item) 또는 필드(field)라고도 한다. 정보의 측면에서 볼 때 이 속성은 그 자체만으로는 중요한 의미를 표현하지 못하기 때문에 단독으로 존재하지는 못한다. 앞의 예에서 각 속성들 즉, 학번, 이름, 학과는 개별적으로는 우리에게 어떤 정보를 제공해 주지 못하지만 이것들이 모여 학생이라는 개체를 구성해서 표현할 때는 큰 의미를 제공하고 있다. 물론 각 속성이 갖는 값은 시간에 따라 변할 수도 있다. 일반적으로, 한 속성이 취할 수 있는 모든 값을 총칭해서 도메인(domain)이라 한다.
릴레이션
주로 테이블(Table)과 같은 의미로 사용되며, 데이터의 집합을 의미한다. 튜플(Tuple)과 애트리뷰트(Attribute)로 구성되어 있다.
릴레이션의 특징
1. 릴레이션에 포함된 튜플들은 모두 다르다.
2. 릴레이션에 포함된 튜플 사이에는 순서가 없다.
3. 튜플들의 삽입, 삭제등의 작업으로 인해 릴레이션은 시간에 따라 변한다.
4. 릴레이션 스키마를 구성하는 애트리뷰트들 간의 순서는 중요하지 않다.
5. 애트리뷰트의 유일한 식별을 위해 애트리뷰트의 명칭은 유일해야 하지만, 애트리뷰트를 구성하는 값은 동일한 값이 나올수 있다.
6. 릴레이션을 구성하는 튜플을 유일하게 식별하기 위해 애트리뷰트들의 부분집합을 키로 설정한다.
7. 애트리뷰트는 더 이상 쪼갤 수 없는 원자 값만을 저장한다.
릴레이션 스키마
릴레이션 스키마는 릴레이션에 어떤 정보가 담길지를 정의한다. 도서 릴레이션은 도서번호, 도서이름, 출판사, 가격이라는 정보를 정의하고 있는데, 각 열을 속성(attribute)이라고 한다. 속성에는 각각의 이름이 있으며 우리는 그 이름을 보고 어떤 정보가 담기는 알 수 있다. 하지만 컴퓨터는 속성만으로 어떤 타입의 데이터인지 알 수 없다. 따라서 각 속성들이 어떤 값을 가질 수 있는지를 도메인(domain)이라는 용어를 사용하여 정의한다. 또한 릴레이션이 몇 개의 속성을 가지는가를 나타내기 위해 차수(degree)라는 용어를 사용한다.

릴레이션 인스턴스
릴레이션 인스턴스는 릴레이션 스키마에 실제로 저장된 데이터의 집합이다. 도서 릴레이션을 보면 도서번호가 1부터 5까지 총 다섯 권의 데이터가 저장된 것을 알 수 있다. 릴레이션에서 행을 튜플(tuple)이라고 한다. 튜플은 릴레이션 인스턴스의 각각의 행을 나타낸다. 각 튜플의 속성 값은 스키마에서 정의한 도메인 값으로 구성되며 튜플이 가지는 속성의 개수는 스키마의 차수와 동일하다. 또한 릴레이션 내의 모든 튜플들은 서로 중복되지 않아야 한다. 릴레이션에 저장된 튜플의 수를 카디날리티라고 한다. 카디날리티는 튜플의 삽입, 삭제, 수정 등에 따라 수시로 변한다.
뷰
사용자에게 접근이 허용된 자료만을 제한적으로 보여주기 위해 하나 이상의 기본 테이블로부터 유도된, 이름을 가지는 가상 테이블이다.
- 뷰는 저장장치 내에 물리적으로 존재하지 않지만 사용자에게 있는 것처럼 간주된다.
- 뷰는 데이터 보정작업, 처리과정 시험 등 임시적인 작업을 위한 용도로 활용된다.
- 뷰는 조인문의 사용 최소화로 사용상의 편의성을 최대화한다.
뷰의 특징
- 기본 테이블로부터 유도된 테이블이기 때문에 기본 테이블과 같은 형태의 구조를 사용하며, 조작도 기본 테이블과 거의 같다.
- 가상 테이블이기 때문에 물리적으로 구현되어 있지 않다.
- 데이터의 논리적 독립성을 제공할 수 있다.
- 필요한 데이터만 뷰로 정의해서 처리할 수 있기 때문에 관리가 용이하고 명령문이 간단해진다.
- 뷰를 통해서만 데이터에 접근하게 하면 뷰에 나타나지 않는 데이터를 안전하게 보호하는 효율적인 기법으로 사용할 수 있다.
- 기본 테이블의 기본키를 포함한 속성(열) 집합으로 뷰를 구성해야지만 삽입, 삭제, 갱신, 연산이 가능하다.
- 일단 정의된 뷰는 다른 뷰의 정의에 기초가 될 수 있다.
- 뷰가 정의된 기본 테이블이나 뷰를 삭제하면 그 테이블이나 뷰를 기초로 정의된 다른 뷰도 자동으로 삭제된다.
뷰의 장·단점
- 장점
- 논리적 데이터 독립성을 제공한다.
- 동일 데이터에 대해 동시에 여러사용자의 상이한 응용이나 요구를 지원해 준다.
- 사용자의 데이터 관리를 간단하게 해준다.
- 접근 제어를 통한 자동 보안이 제공된다.
- 단점
- 독립적인 인덱스를 가질 수 없다.
- ALTER VIEW 문을 사용할 수 없다. 즉 뷰의 정의를 변경할 수 없다.
- 뷰로 구성된 내용에 대한 삽입, 삭제, 갱신, 연산에 제약이 따른다.
SQL에서의 뷰 활용
생성
CREATE VIEW 뷰이름[(속성이름[,속성이름])]AS SELECT문;
삭제
※ 뷰는 ALTER 문을 사용하여 변경할 수 없으므로 필요한 경우는 삭제한 후 재생성한다.
DROP VIEW 뷰이름 RESTRICT or CASCADE
- RESTRICT : 뷰를 다른곳에서 참조하고 있으면 삭제가 취소된다. - CASCADE : 뷰를 참조하는 다른 뷰나 제약 조건까지 모두 삭제된다.
키
- 데이터베이스에서 조건에 만족하는 튜플을 찾거나 순서대로 정렬할 때 다른 튜플들과 구별할 수 있는 유일한 기준이 되는 Attribute(속성)이다.
기본키
- 후보키 중에서 선택한 주키(Main Key)
- 한 릴레이션에서 특정 튜플을 유일하게 구별할 수 있는 속성
- Null 값을 가질 수 없다.
- 기본키로 정의된 속성에는 동일한 값이 중복되어 저장될 수 없다.
후보키
- 릴레이션을 구성하는 속성들 중에서 튜플을 유일하게 식별할 수 있는 속성들의 부분집합을 의미한다.
- 모든 릴레이션은 반드시 하나 이상의 후보키를 가져야 한다.
- 릴레이션에 있는 모든 튜플에 대해서 유일성과 최소성을 만족시켜야 한다.
대체키
- 후보키가 둘 이상일 때 기본키를 제외한 나머지 후보키들을 말한다.
- 보조키라고도 한다.
슈퍼키
- 슈퍼키는 한 릴레이션 내에 있는 속성들의 집합으로 구성된 키로서 릴레이션을 구성하는 모든 튜플 중 슈퍼키로 구성된 속성의 집합과 동일한 값은 나타내지 않는다.
- 릴레이션을 구성하는 모든 튜플에 대해 유일성은 만족하지만, 최소성은 만족시키지 못한다.
외래키
- 외래키는 참조되는 릴레이션의 기본키와 대응되어 릴레이션 간에 참조 관계를 표현하는데 중요한 도구로 사용된다.
- 관계(Relation)를 맺고 있는 릴레이션 R1, R2에서 릴레이션 R1이 참조하고 있는 릴레이션 R2의 기본키와 같은 R1 릴레이션의 속성이다.
- 외래키로 지정되면 참조 테이블의 기본키에 없는 값은 입력할 수 없다.
SQL에서의 테이블 활용
테이블 생성
CREATE TABLE 테이블 이름 (
컬럼명1 DATATYPE [DEFAULT 형식],
컬럼명2 DATATYPE [DEFAULT 형식],
컬럼명3 DATATYPE [DEFAULT 형식]
);
- 테이블 생성시 대/소문자 구분은 하지 않는다. (기본적으로 테이블이나 컬럼명은 대문자로 만들어진다.)
- DATE 유형은 별도로 크기를 지정하지 않는다.
- 문자 데이터 유형은 반드시 가질 수 있는 최대 길이를 표시해야 한다.
- 컬럼과 컬럼의 구분은 콤마로 하되, 마지막 컬럼은 콤마를 찍지 않는다.
- 컬럼에 대한 제약조건이 있으면 CONSTRAINT를 이용하여 추가할 수 있다.
테이블 수정
ALTER TABLE 테이블명;
테이블 삭제
DROP TABLE 테이블명 [CASCADE CONSTRAINT];
- DROP TABLE 명령어를 사용하면 테이블의 모든 데이터 및 구조를 삭제한다.
- CASCADE CONSTRAINT 옵션은 해당 테이블과 관계가 있었던 참조되는 제약조건에 대해서도 삭제한다는 것을 의미한다.
- (SQL Server에서는 CASCADE 옵션이 존재하지 않는다. 테이블 삭제 전에 참조하는 FOREIGN KEY 제약 등을 먼저 삭제해야 한다.)
테이블 목록 조회
SHOW TABLES;
테이블 조회
SELECT * FROM 테이블명;
컬럼 추가 (ADD COLUMN)
ALTER TABLE 테이블명 ADD 추가할 컬럼명 데이터 유형;
컬럼 수정 (MODIFY COLUMN)
ALTER TABLE 테이블명 MODIFY COLUMN 수정할 컬럼명;
- MODIFY COLUMN 사용 시 주의사항
- 해당 컬럼의 크기를 늘릴 수는 있지만 줄이지는 못한다. 이는 기존의 데이터가 훼손될 수 있기 때문이다.
- 해당 컬럼이 NULL 값만 가지고 있거나 테이블에 아무 행도 없으면 컬럼의 폭을 줄일 수 있다.
- 해당 컬럼이 NULL 값만을 가지고 있으면 데이터 유형을 변경할 수 있다.
- 해당 컬럼의 DEFAULT 값을 바꾸면 변경 작업 이후 발생하는 행 삽입에만 영향을 미치게 된다.
- 해당 컬럼에 NULL 값이 없을 경우에만 NOT NULL 제약조건을 추가할 수 있다.
컬럼명 수정 (RENAME COLUMN)
테이블을 생성하면서 만들어졌던 컬럼명을 변경해야 할 경우에 사용한다.
ALTER TABLE 테이블명 RENAME COLUMN 변경해야할 컬럼명 TO 새로운 컬럼명;
컬럼 삭제 (DROP COLUMN)
ALTER TABLE 테이블명 DROP COLUMN 삭제할 컬럼명;
제약조건
- 제약조건(constraint) : 제약조건은 사용자가 원하는 조건의 데이터만 유지하기 위한 특정 컬럼에 설정하는 제약이다. 테이블을 생성할 때 제약조건을 반드시 기술할 필요는 없다.
- PRIMARY KEY
- 테이블에 저장된 행 데이터를 고유하게 식별하기 위한 기본키 정의.
- 하나의 테이블에 하나의 기본키 제약만 정의할 수 있다.
- 기본키 제약을 정의하면 DBMS는 자동으로 UNIQUE 인덱스를 생성하며, 기본키를 구성하는 컬럼에는 NULL을 입력할 수 없다.
- UNIQUE KEY
- 테이블에 저장된 행 데이터를 고유하게 식별하기 위한 고유키를 정의한다.
- 단, NULL은 고유키 제약의 대상이 아니므로, NULL 값을 가진 행이 여러 개가 있더라도 고유키 제약 위반이 되지 않는다.
- NOT NULL
- NULL 값의 입력을 금지한다.
- 디폴트 상태에서는 모든 컬럼에서 NULL을 허가하고 있지만, 이 제약을 지정함으로써 해당 컬럼은 입력 필수가 된다.
- CHECK
- 입력할 수 있는 값의 범위 등을 제한한다. CHECK 제약으로는 TRUE or FALSE로 평가할 수 있는 논리식을 지정한다.
- FOREIGN KEY
- 관계형 데이터베이스에서 테이블 간의 관계를 정의하기 위해 기본키를 다른 테이블의 외래키로 복사하는 경우 외래키가 생성된다.
- 외래키 지정시 참조 무결성 제약 옵션을 선택할 수 있다.
각주
- 밤공기후하후하, 〈Database - 데이터베이스에서 테이블, Table이란 무엇인가 〉, 2019-05-28
- 김성현, 〈테이블(Table), 필드(Field), 열(Column), 행(Row)〉, 2019-04-18
- 양햄찌, 〈데이터베이스 릴레이션 용어 - 속성(애트리뷰트), 튜플, 도메인, 차수, 카디날리티 〉, 2019-03-01
- 개발자, 〈데이터베이스 릴레이션의 특징, 용어 〉, 2013-03-16
- 돌딱, 〈관계형 데이터베이스의 구조 〉, 2020-03-18
- Lim-ky, 〈DataBase 키(Key)의 개념 및 종류〉, 2017-10-23
- 개발이 하고 싶어요, 〈https://hyeonstorage.tistory.com/]〉
- 코딩팩토리, 〈뷰란 무엇인가?〉, 2018-08-18
같이 보기


